Scikit-learn是Python最流行的机器学习库之一,它提供了用于数据分析和机器学习任务的广泛工具,从简单的线性回归到高级聚类算法。
在本文当中,小编将简单介绍Linux系统安装和使用Scikit-learn的简单步骤。如果你想了解Scikit-learn方面的内容,那么一起来看看吧。
什么是Scikit-learn?
Scikit-learn(也称为sklearn)是用于机器学习任务的免费开源Python库,它以NumPy、SciPy和matplotlib等其它Python库为基础,为复杂的机器学习算法提供了一个简单的界面,其主要功能包括:
- 监督学习(例如分类、回归)
- 无监督学习(例如聚类、降维)
- 模型评估和验证
- 数据预处理工具
- 支持多种数据格式和模型部署工具
在Linux系统中安装Python
Scikit-learn是基于Python构建的,因此需要在系统上安装Python,可以在终端中输入以下命令来检查Python是否已安装:
python3 --version
如果未安装Python,则可以通过运行以下命令进行安装:
sudo apt install python3 [Debian、Ubuntu和Mint系统] sudo yum install python3 [RHEL/CentOS/Fedora和Rocky/AlmaLinux系统] sudo emerge -a sys-apps/python3 [Gentoo Linux系统] sudo apk add python3 [Alpine Linux系统] sudo pacman -S python3 [Arch Linux系统] sudo zypper install python3 [OpenSUSE系统] sudo pkg install python3 [FreeBSD系统]
在Linux系统中安装Pip
Pip是用于安装Scikit-learn等Python库的Python包管理器,要检查pip是否已安装,请运行以下命令:
pip3 --version
如果未安装pip,请使用以下命令安装:
sudo apt install python3-pip [Debian、Ubuntu和Mint系统] sudo yum install python3-pip [RHEL/CentOS/Fedora和Rocky/AlmaLinux系统] sudo emerge -a dev-python/pip [Gentoo Linux系统] sudo apk add py3-pip [Alpine Linux系统] sudo pacman -S python-pip [Arch Linux系统] sudo zypper install python3-pip [OpenSUSE系统] sudo pkg install py38-pip [FreeBSD系统]
在Linux中安装Scikit-learn
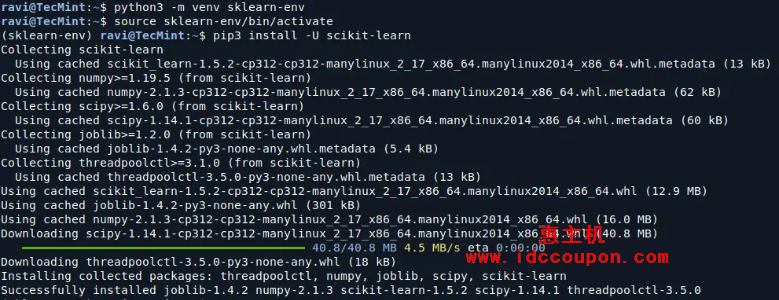
现在创建一个虚拟环境(venv)并安装scikit-learn。请注意,虚拟环境虽说不是必须要安装,但强烈建议安装,以避免与其他软件包发生潜在冲突:
python3 -m venv sklearn-env source sklearn-env/bin/activate pip3 install -U scikit-learn
此命令将下载并安装最新版本的Scikit-learn及其依赖项(例如NumPy和SciPy),根据你自身的网络速度,这可能需要几分钟到半小时不等:
安装完成后,可以通过在Python中导入来验证Scikit-learn是否正确安装:
python3 -m pip show scikit-learn #显示scikit-learn版本和位置 python3 -m pip freeze #显示环境中所有已安装的包 python3 -c "import sklearn; sklearn.show_versions()"
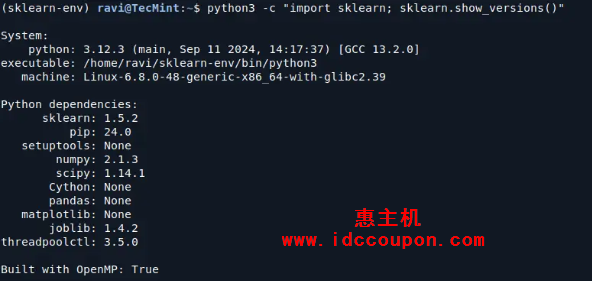
如果没有出现错误,并且打印了Scikit-learn的版本号,则表示安装成功。
在Linux中使用Scikit-learn
安装Scikit-learn之后,现在就可以开始使用它了,下面是有关如何使用Scikit-learn进行各种机器学习任务的基本示例演示。
示例1:导入Scikit-learn并加载数据集
Scikit-learn提供了几个用于学习的内置数据集,其中一个流行的数据集是“Iris(鸢尾花)”数据集,其中包含有关不同种类Iris的数据。要加载Iris数据集,请使用以下代码:
from sklearn.datasets import load_iris # Load the dataset iris = load_iris() # Print the features and target labels print(iris.data) print(iris.target)
示例2:将数据拆分为训练集和测试集
在应用机器学习模型之前,将数据集分成训练集和测试集非常重要,这可以确保模型在数据的一个子集上进行训练,在另一个子集上进行测试,从而防止过度拟合。一般情况下,可以使用Scikit-learn提供的train_test_split 方法拆分数据:
from sklearn.model_selection import train_test_split
# Split the data into 80% training and 20% testing
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=42)
print("Training data:", X_train.shape)
print("Testing data:", X_test.shape)
示例3:训练机器学习模型
接下来让我们借助一个简单的分类器,例如支持向量机(SVM)来训练一个机器学习模型,对Iris进行分类:
from sklearn.svm import SVC
# Create an SVM classifier
model = SVC()
# Train the model on the training data
model.fit(X_train, y_train)
# Predict on the test data
y_pred = model.predict(X_test)
print("Predicted labels:", y_pred)
示例4:评估模型
训练模型后,评估其性能非常重要,你可以使用准确率等指标来查看模型的性能:
from sklearn.metrics import accuracy_score
# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
这将打印模型的准确度,以表示模型在测试数据上做出的正确预测的百分比。
结论
以上就是Linux系统安装和使用Scikit-learn简单步骤,同时通过几个示例进行简单演示,包括使用Scikit-learn加载数据集、拆分数据、训练机器学习模型以及评估模型的性能。
实际上,Scikit-learn是一款功能强大且易于使用的Python机器学习工具。通过以上过程步骤,你可以开始你的机器学习之旅,并探索Scikit-learn提供的大量算法和技术。通过练习和试验不同的算法、数据集和模型评估技术,你将能够为现实问题构建有效的机器学习解决方案。